The Cost of Loading in a Loop
We recently saw some pretty dramatic performance degradation on an API endpoint consumed by our mobile applications. This particular endpoint is responsible for supplying our mobile apps with category and product data on open and it’s degraded performance meant the apps were very slow and clunky when starting up. We run multiple instances of this application, all running the same code rebranded and containing customer specific data. I mention this because it provides the opportunity to gauge performance of each instance where the only variable is the size and structure of our customers’ data.
Triaging the issue it was very apparent the performance was not great across all instances, but it was particularly bad for a single instance. I was happy to see this because it usually points to inefficient data loading and those tend to be low effort/high impact fixes. I grabbed a copy of non-prod data exhibiting the same behavior and got my envrionment ready for some profiling.
I like to use Blackfire for profiling. It’s very easy to install and visualize profiles. You can always use xdebug’s profiling, which is equally easy in most instances. My preference for Blackfire comes from past experience with PhpStorm and KCachegrind crashing when loading the profiler output from the bloatware that is Magento.
Blackfire’s client ran 10 requests to my problem endpoint and I started looking
at the stack for trouble spots. The recorded response time was 3.54s, OUCH!
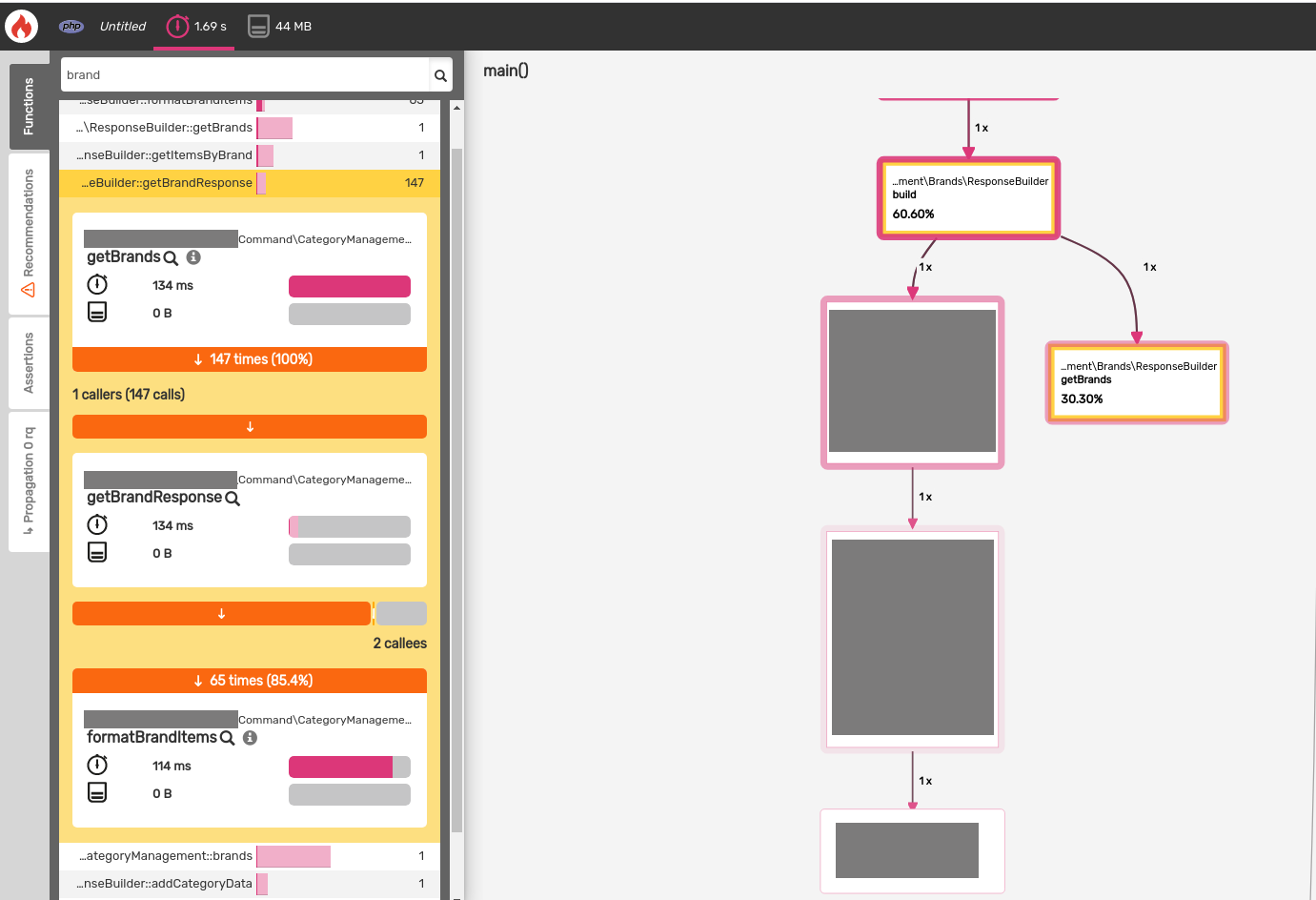
Taking a look at the call graph I was trying to spot function calls with a high
percentage of total time with multiple calls. I stumbled across getBrandItems
called 147x accounting for 59% (2.09s) of my response time. Perfect, time to
look at the code.
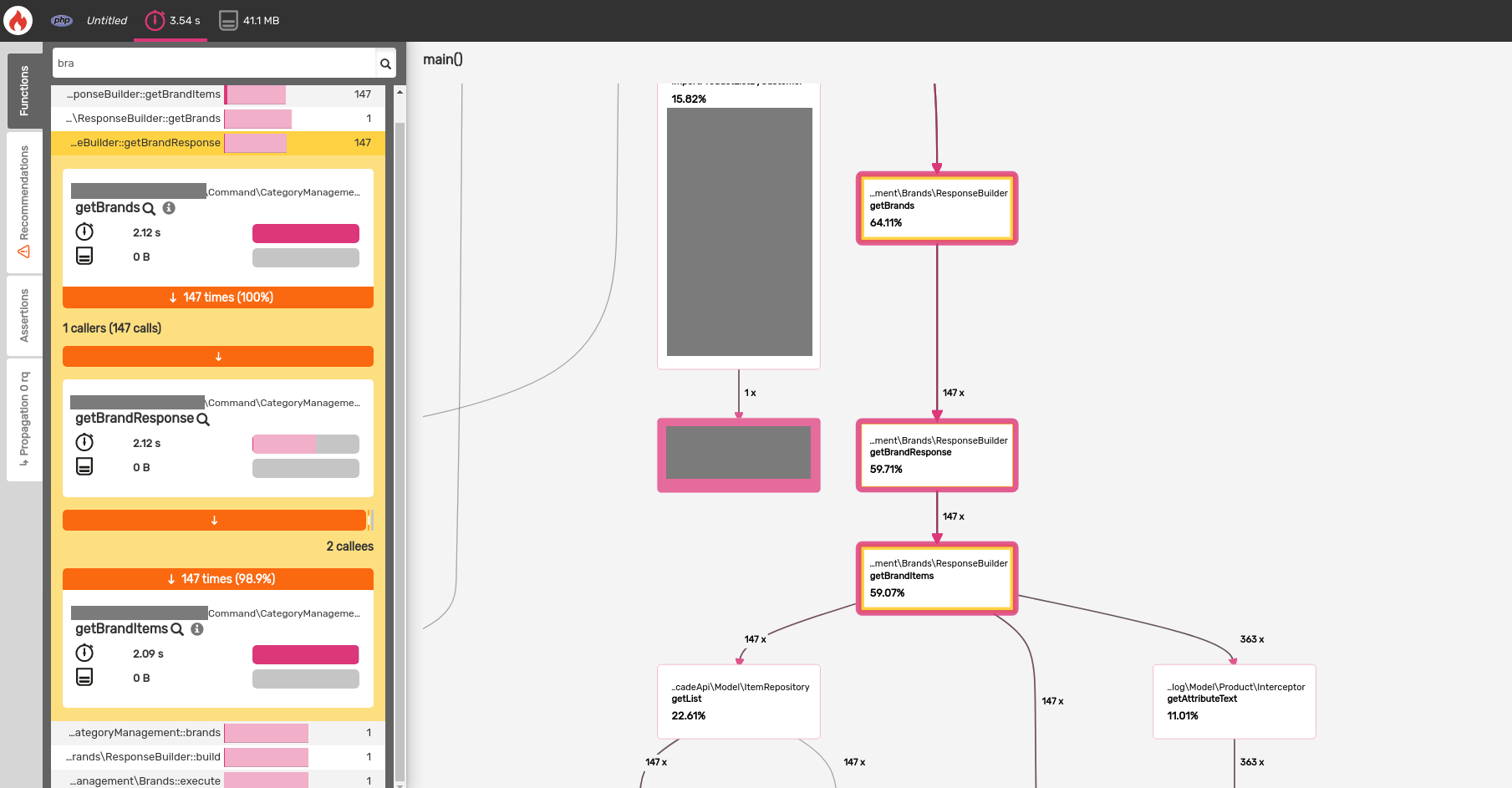
This endpoint returns the category tree and products for the mobile app. When
building the response, each category is passed into getBrandItems to populate
the category items. The application was going back to the database for every
category, 147 in this instance, and retrieving the products per category. This
could be better, but I was also curious how much product overlap there was
between categories. I analyzed a few response payloads and counted the number
of instances for each SKU.
The payloads had an average of 206 unique products. There were usually ~50 products appearing only once, ~150 appearing twice and ~6 appearing three times! Not only were we making too many round trips to the database, we were often fetching the same data.

Now that we’ve identified the problem via the profiler data and a little legwork it was optimization time. In a perfect world we’d have started looking at what this endpoint returns, but we can’t break the existing service contract so we have to work with what’s currently in place. The looped product loads are the main bottleneck and I began there.
Prior to entering the loop we have a collection of categories we need the child products of. Within Magento we can use these category IDs as search criteria for the product repository. This will let us load all the products needed in for the response with a single query. I now had all the products for the categories in a single collection and the product data included a list of associated category IDs. But the category associations aren’t in a format I could easily use without iterating over all the products for each category. My database was the biggest bottleneck here and the improvement would have been significant even doing something lazy and silly like the pseudo code below
foreach ($categories as $category) {
$categoryProducts = [];
foreach ($products as $product) {
if (in_array($category->getId(), $product->getCategoryIds())) {
$categoryProducts[] = $product;
}
}
$category->setProducts($categoryProducts);
}…but this meant I would iterate over the same data 147 times. Instead I can pre-sort the product into a hash map using the category ID as the key. This will let me iterate over the products once and use the result when iterating through the categories. The ned result looked something like this
$categoryProductsMap = [];
foreach ($products as $product) {
foreach ($product->getCategoryIds() as $categoryId) {
$categoryProductsMap[$categoryId][] = $product;
}
}
foreach ($categories as $category) {
$category->setProducts($categoryProductsMap[$category->getId()] ?? []);
}With the actual code in place I went back re-ran the Blackfire CLI and profiled the endpoint. The results looked great! Blackfire reported a 52% reduction in response time with only a 7% increase in memory consumption.
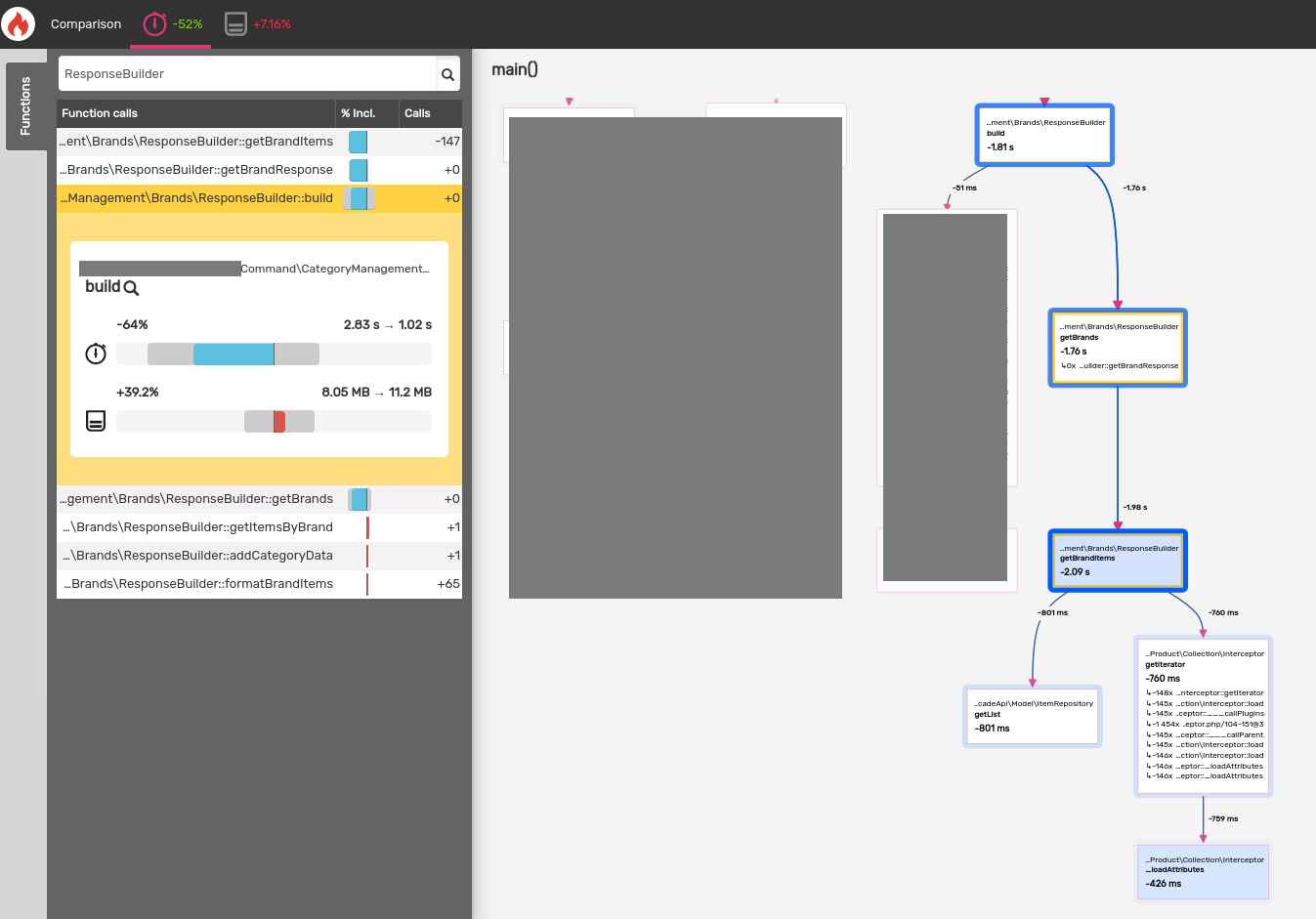
The refactor reduced the total time of the getBrands function from 2.12s to
134ms!