Fun With MongoDB Atlas Analytics Nodes
Our data teams maintain a few workflows where application data is fetched from our operational APIs. This is generally done for a handful of applications touching multiple datasets and applying business logic without any materialized view of the resulting data. This is a separate issues we are addressing, so I won’t rant about it further.
Initially the data team was calling the same services and deployments as our end-users and this worked… until it didn’t. As you can imagine, one day the competing requests between users and data exhausted resources and our service performance was degraded. The quick fix was creating a separate deployment of these services in our kubernetes cluster connected to analytics nodes in MongoDB Atlas for workload isolation.
Use analytics nodes to isolate queries which you do not wish to contend with your operational workload. Analytics nodes help handle data analysis operations, such as reporting queries from BI Connector for Atlas. Analytics nodes have distinct replica set tags which allow you to direct queries to desired regions.
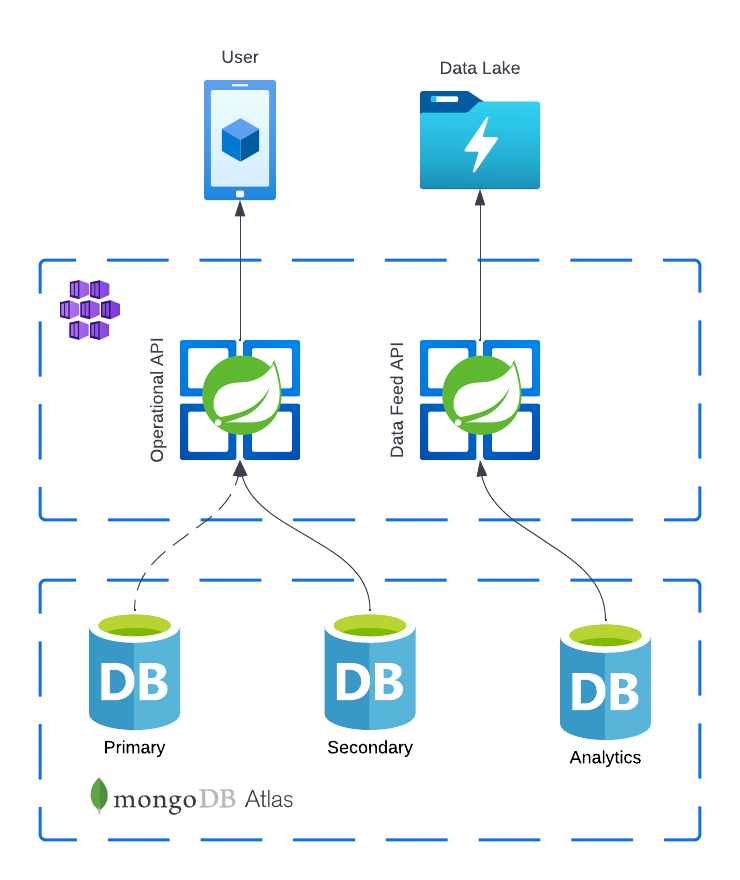
With the isolated deployments above our requests have a read preference for the secondary MongoDB node and can read from
the primary node if the secondary is unavailable. The data lake requests are routed to a separate deployment of the same
service connected to an analytics node. This accomplished in the application connections string by specifying the
readPreference and readPreferenceTags.
Operational Services
readPreference=secondaryPreferred&readPreferenceTags=workloadType:OPERATIONAL
Data Feed Services
readPreference=secondaryPreferred&readPreferenceTags=nodeType:ANALYTICS
Those familiar with the documentation
of the secondaryPreferred read preference have probably already noticed our error. Unfortunately, we were not. This
solved our issues, and we were serving requests for users and data feeds without issues for months.
One day we noticed a typo in our data feed connection string our feed deployments had not been reading from our analytics nodes. They were instead reading from the secondary nodes.
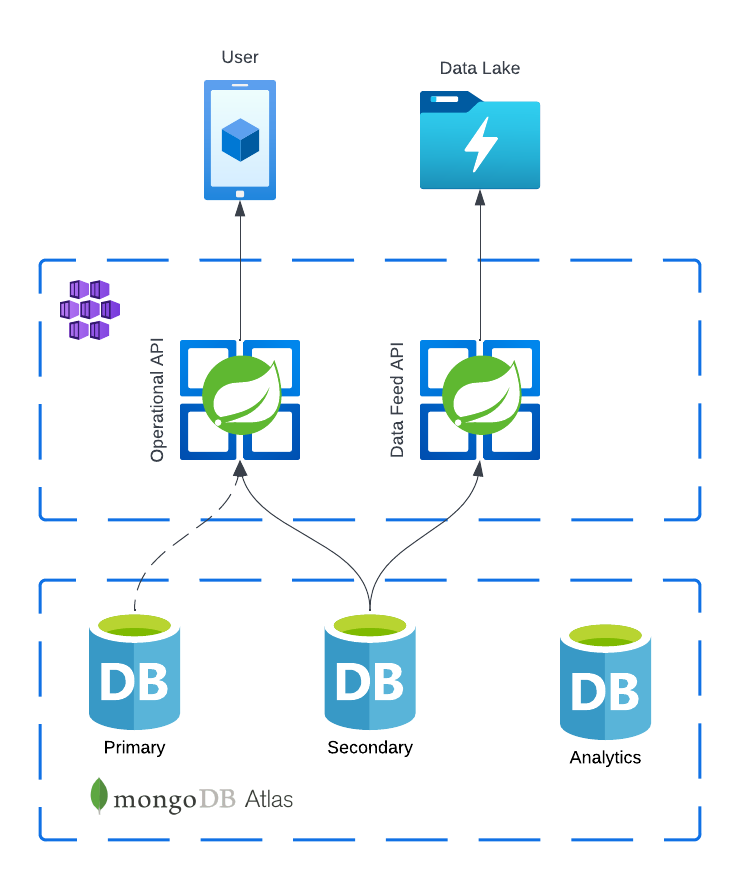
We fixed the connection string and felt as if we had dodged a bullet. Now our workloads were properly isolated, and we were safe.
In reality that desired behavior was not happening. As soon as the analytics node stopped responding to reads our primary node, already under heavy write load, saw an increase in read operations eventually degrading the primary node’s performance and promoting the secondary node as the primary. During this period our user facing services would degrade as read performance suffered. Why would this happen? We thought this risk was mitigated by isolating the workloads.
Analytics nodes are located in the same shard as the primary and secondary nodes. The secondary node has higher priority resource access than the analytics nodes. This makes sense, keeping the replication lag as low as possible on the secondary and protecting the operational workloads. This can create high replication lag for the analytics node during periods with high write throughput.
Turns out MongoDB was doing exactly what we told it to do in our feed deployment connection string.
When the read preference includes a tag set list (an array of tag sets), the client attempts to find secondary members with matching tags (trying the tag sets in order until a match is found). If matching secondaries are found, the client selects a random secondary from the nearest group of matching secondaries. If no secondaries have matching tags, the client ignores tags and reads from the primary.
Using the readPreference=secondaryPreferred read preference with readPreferenceTags=nodeType:ANALYTICS we were
instructing MongoDB to read from the primary node when the analytics nodes were unavailable. We had not fully isolated
the workflow. We had actually linked the feed services to our primary operation node by mistake.
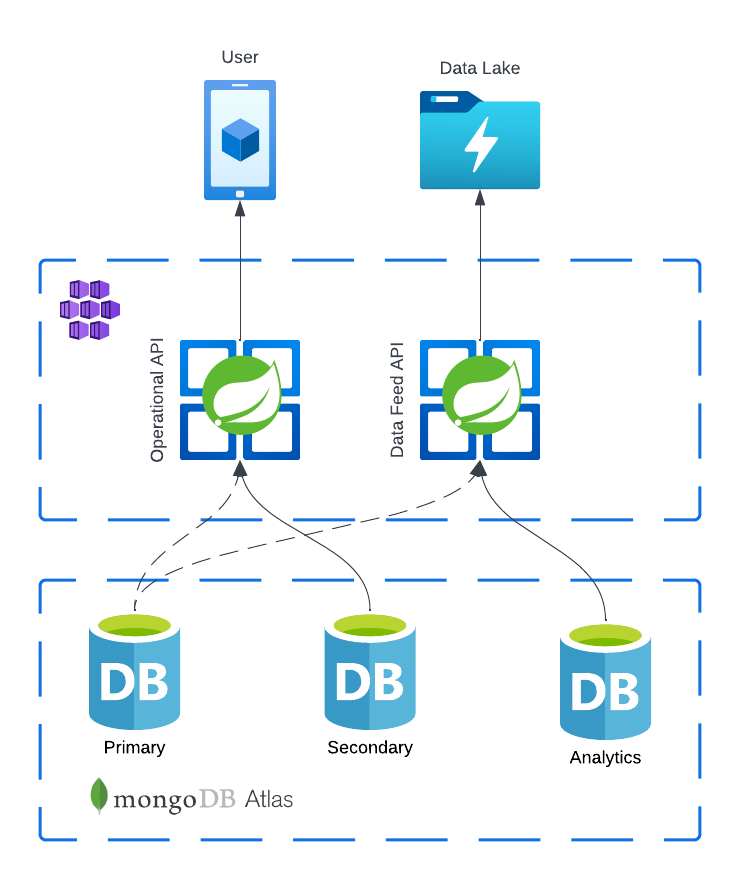
We actually wanted the behavior of readPreference=secondary.
Operations read only from the secondary members of the set. If no secondaries are available, then this read operation produces an error or exception.
Changing the read preference from secondaryPreferred to secondary on our feed deployment connection strings matched
our intention and restored stability to our user facing services.
TLDR; sometimes you have to RTFM